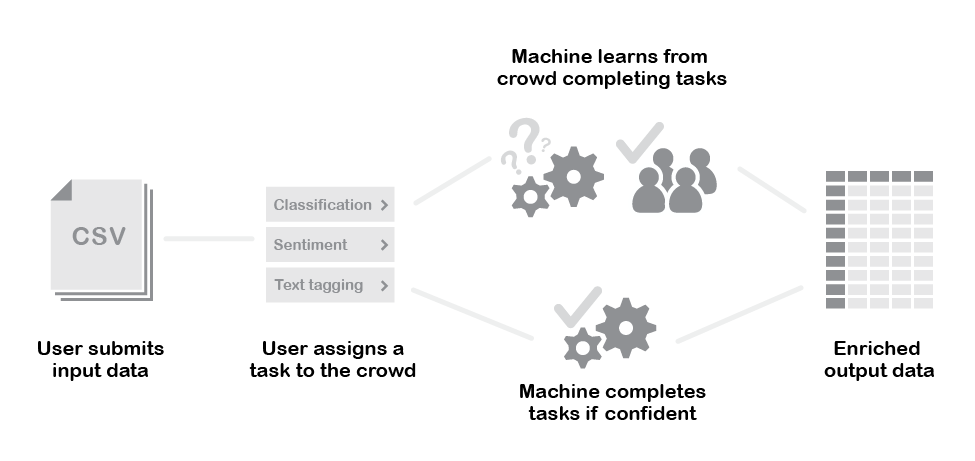
An annotation tool for extracting and structuring data in financial documents
A major bank hired Workfusion to automate their data extraction processes. The client had an existing, highly manual workflow and wanted to use our machine learning platform to automatically extract records from financial documents. In addition to improving the speed and cost for extracting this data, the client wanted to be able to use Workfusion on a self-service basis.
When work began, the client's workflow could only be implemented using custom logic that had to be maintained by developers. As the feature owner of the project, I researched, developed, and pitched a redesign of the worker interface that allowed us to achieve the same outcomes with a one-time behind-the-scenes feature implementation.
I then led a front-end development team that implemented my design vision, leading to a successful proof of concept and a $2 million annual contract.
While Engineering was putting together an MVP out of available components, I engaged internal user-facing stakeholders to act as my research team. We discovered a number of inefficient actions that users of the MVP were forced to repeat as they extracted the text, leading to frustration and slow progress.
After understanding the problem, I partnered with Workfusion's Engineering and Data Science leads in order to understand the extent of Workfusion's technical capabilities. I created a prototype experience that was both technically achievable and closed the gaps encountered during my research. The prototype automated repeated actions, put frequently accessed information closer to hand, and allowed Workfusion's machine learning to help workers on the fly.
Even though the scope of the prototype was beyond the initial plan, the results from its usability testing convinced internal stakeholders to assign more engineers to the project. I worked with them as feature owner and front-end developer in order to deliver the project on time and to spec.
- User Research
(2 weeks)My role: Research lead
Team: CS specialist, Sales representative, Business analyst
- Initial Design & Prototype
(3 weeks)My role: Design lead
Team: Head of Engineering, Chief Data Scientist
- Iterative Development
(6 weeks)My role: Feature owner and front-end developer
Team: Two front-end developers
Context
Workfusion was contracted by a major international bank to automate invoice handling within their systems. The bank's existing process required a lot of manual work by junior business analysts, and though this process was outsourced overseas, it was still slow and costly. The client wanted to use Workfusion's automation tools to reduce headcount and improve processing speed.
At the time, Workfusion's tools required input data to be structured before it could be processed by the machine learning algorithm (such as a table, with defined rows and columns). The client's business processes produced only unstructured data (scanned PDF files); one of Workfusion's responsibilities would be to structure that data for the client.
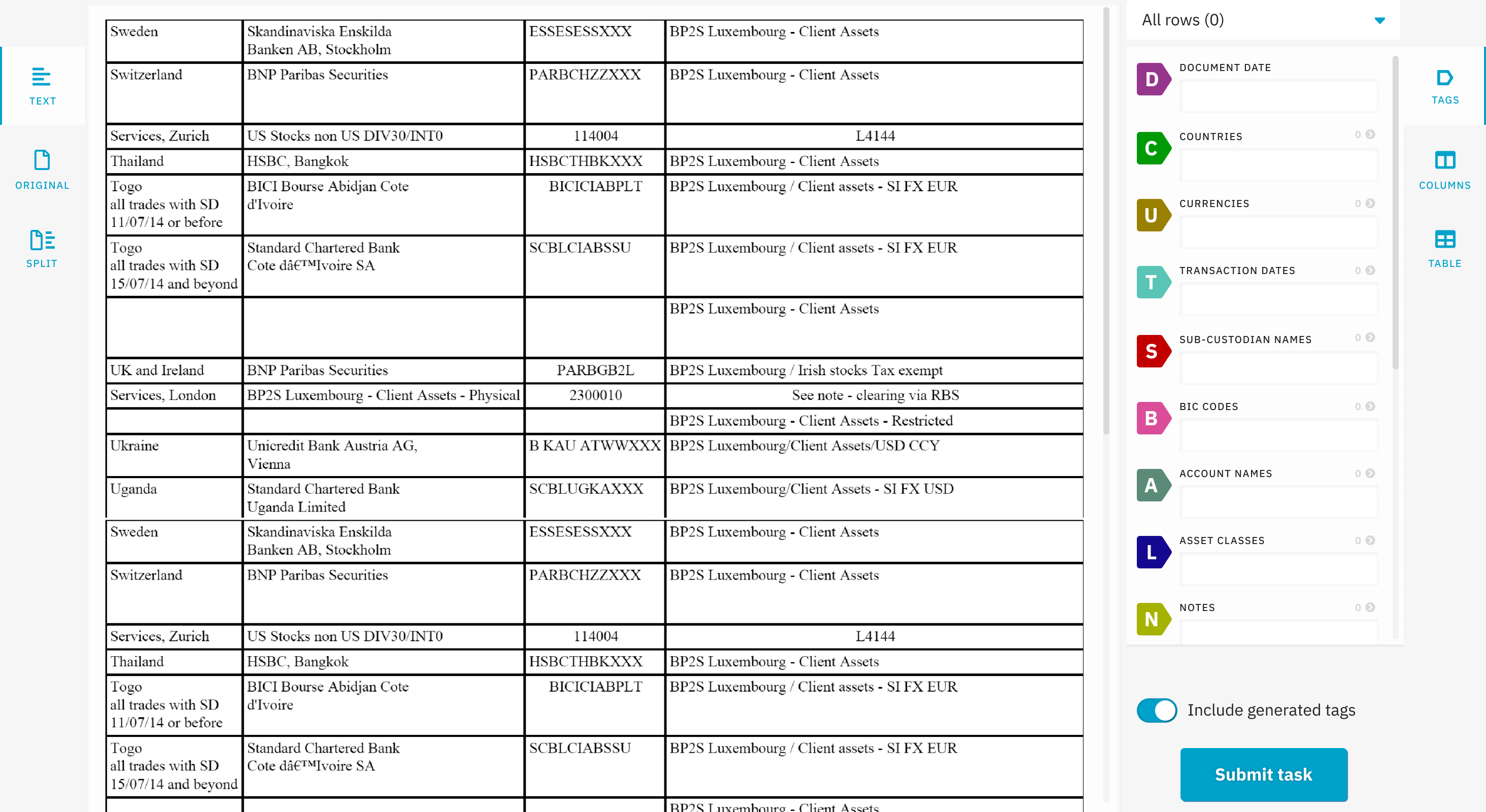
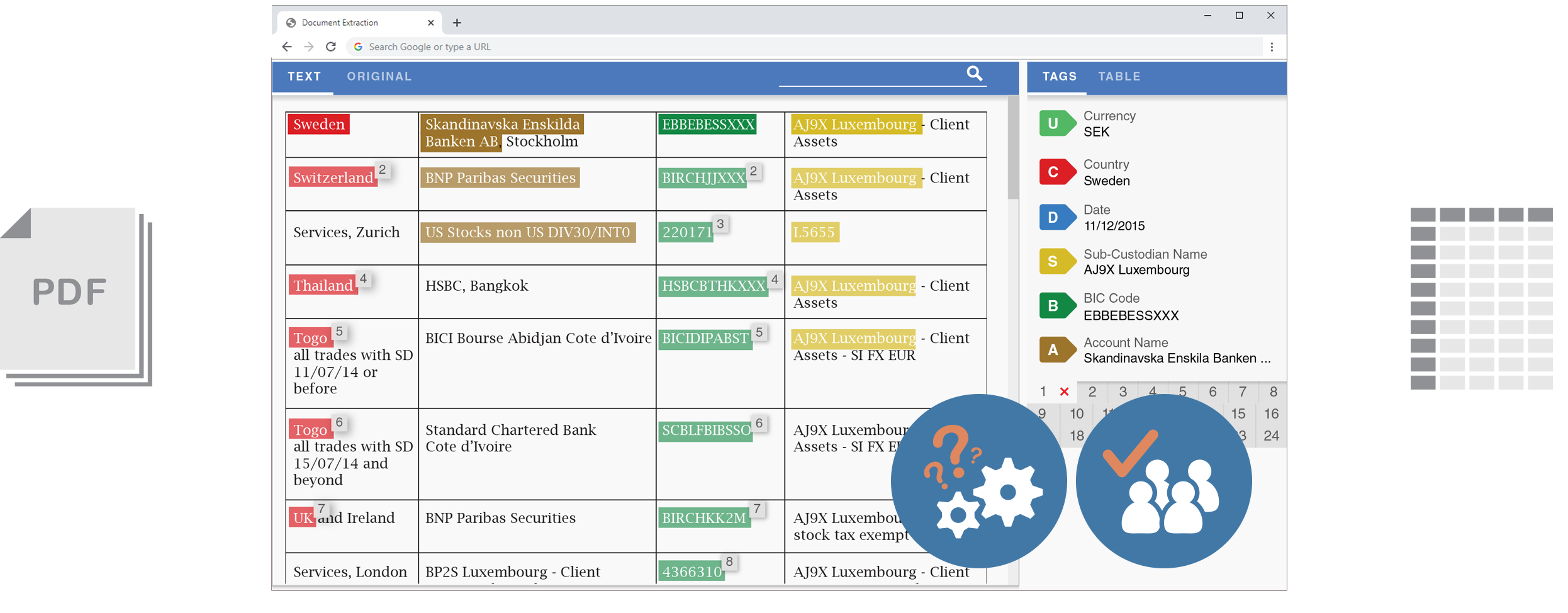
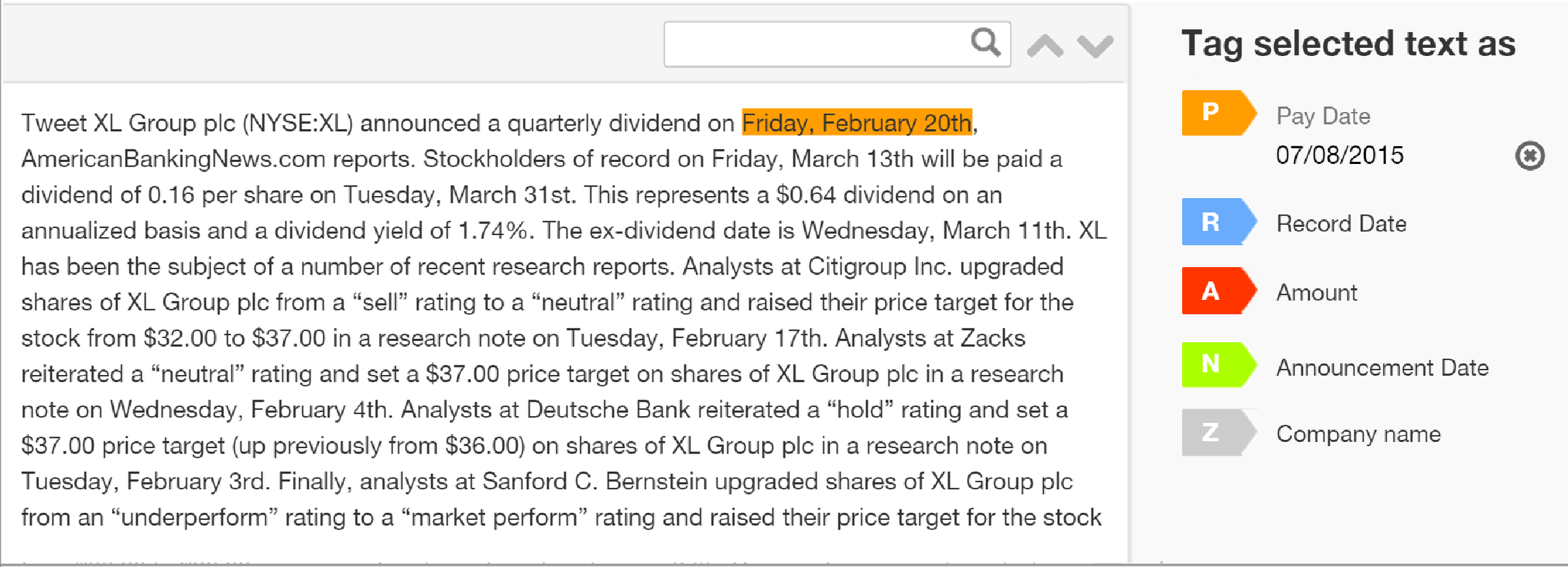
Workfusion had previously developed a simple interface for extracting structured data from plain text. Workers using the tool could highlight text from a paragraph, and tag it by clicking a label or using a hotkey. We decided to use this tool as the basis of our Proof of Concept: we would set up a process inside Workfusion that would convert PDFs to text and present that text to crowd workers to be structured using the tagging interface.
At the time of the project, the workflow logic necessary to make this tool serve our purpose could not be set up within the Workfusion UI. Our management decided that our developers would use custom code to manage the setup for these tasks during the Proof of Concept period. While these developers were focused on exposing the settings to make this setup easier, I proposed that the text extraction tool itself could be improved, in order to process more data at a time and obviate the need for complicated setup on the task publication side.
I took up the role of feature owner on Project Highlight. While a larger team improved the capabilities of the workflow design tool within Workfusion, I would be designing the new Highlight tool and managing two developers to implement the design. The project would be governed by the overall goals of the company and goals of the proof of concept project.
- The goal of Workfusion as a company: Eliminate tedious and error-prone manual Operations work through giving users access to machine learning tools.
- The goal of the Proof of Concept: Improve the information extraction workflow and simplify its design to the point that the client could manage it without our help.
- The goal of Project Highlight: Provide workers with a user experience that allowed them to complete their tagging tasks quickly and with minimal manual work.
My roles
- Customer insight & ideation – Partnered with a business analyst to uncover insights and translate concepts into features that addressed the pain points of our users.
- Planning & scope definition – Worked with the product manager to set requirements and prioritize features, determine the MVP goal.
- Leadership – Presented to stakeholders at Workfusion to get buy-in, worked with senior management to get necessary resources for the project.
- Experience strategy & vision – Developed scenarios and low-fidelity prototypes to share the vision of the solution with the team, and ensure that everyone understood the goal.
- Design execution & validation – Created high-fidelity designs, prototypes, and design specs.
- Implementation – Managed a team of developers and coded alongside them to implement my designs.
Discovery
The project needed to deliver outcomes to two audiences: both the client setting up the tasks, and the workers executing them. To ensure that neither audience was left out, I created a two-pronged strategy for user research.

- The data requester is responsible for an external workflow that delivers him a steady stream of documents. He determines which documents need to be processed.
- The data requester is responsible for determining the flow of the business process and contents of worker tasks. He eares about the quality of the output data.
- Due to the nature of the project, the data requester will not be using Workfusion UIs during the Proof of Concept period, but will communicate needs to our staff.

- The task worker receives tasks submitted by the data requester through Workfusion. He has access to the worker portal, where he chooses which tasks to work on.
- The task worker's main task it tagging the text in documents received based on instructions. The task worker is evaluated on speed of task completion.
- The task worker will be the primary user of Highlight during the Proof of Concept period.
We deployed the text extraction tool to a private instance of Workfusion's crowd computing platform. When the client submitted a document for extraction, the client's employees could log in to this platform and complete the extraction tasks. I took advantage of the platform's existing analytics features to track every worker's task completion time, accuracy, and other metrics. I also performed qualitative testing, setting up think-aloud tests with workers and interviewing them afterwards about their experiences with the tool.
Because the client did not yet have access to the workflow design interface, I could not directly observe them using it. Instead, I brought together the expertise of several colleagues working on the Proof of Concept:
- I interviewed our Customer Success specialists and sat in on support calls from other clients, to understand where clients had trouble with the workflow design interface.
- I learned about the logic we were implementing for the Proof of Concept workflow from our developers, to understand what data the client was sending us, and how it needed to flow through the system.
- I ran a co-design workshop with our data science team in order to understand what format the final data would need to be in, and brainstorm ways in which our automation algorithms might be applied to the worker's interface.
The first set of issues stemmed from the inability of our legacy extraction tool to group extracted data together. The machine learning algorithm could not infer that labels in the same row of the table were semantically connected. The Proof of Concept workflow could only get around this problem in two steps: one worker would have to tag every row in the table as an individual entity, and then Workfusion would generate a task for tagging each row one at a time. This was a complicated flow to set up, and bugs in our backend would interrupt tasks from moving through it.
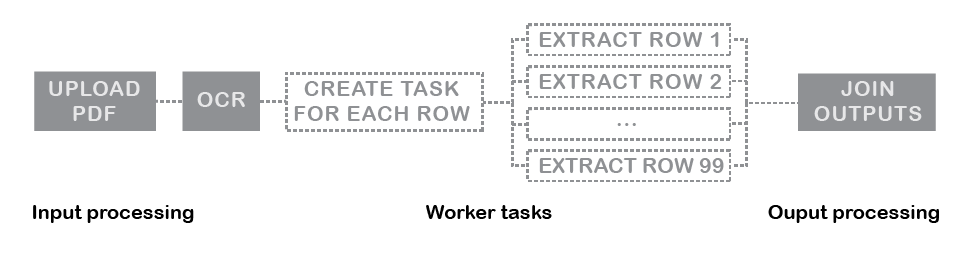
This was also a bad experience for the workers. A worker had to open a task with the entire source document, then scroll down to find the one row assigned to them. The necessary labels would go off-screen as the worker scrolled down, requiring the worker to memorize the labels and their hotkeys. Ultimately, the worker wasted a lot of time scrolling, leading to very slow progress on document extraction.
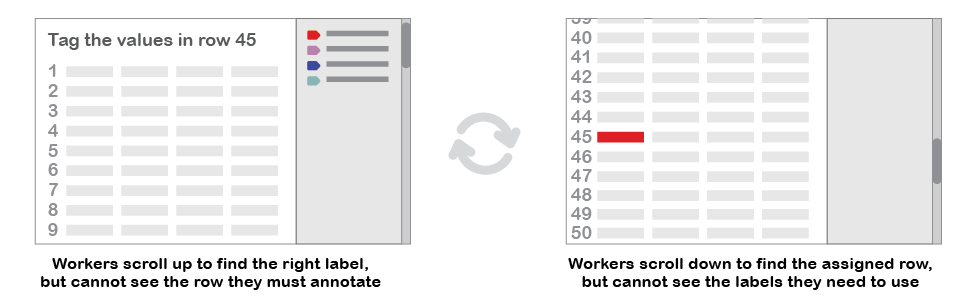
The necessity of breaking each task up into rows compounded the problems with the worker interface. Inefficiencies with tagging a single row multiplied with every row in the source document. A typical table with 4 columns and 50 rows might take 30 minutes to extract: a worker would have to wait for the system to generate 50 tasks, load each one in turn, struggle with the UI, then wait for the responses to be stitched together back into one document.

This was the best-case scenario. Often, the OCR would fail to correctly extract plain text from the input PDF file. Workers could not recover from this exception within the tool. They would have to mark the document's contents as corrupted, discharging the task, and revert to the client's existing, manual transcription tool.
Due to the frustrating experience of using our tool, many workers would mark correctly OCR'ed files as corrupted, so that they could go back to using their familiar program. 10% of documents were legitimately marked as corrupted, but an additional 15% were illegitimately marked. This meant that we would fail to process every fourth document submitted by the client, and users would need to manually merge its contents into their database.
Design Process
Based on the scenarios of use gathered from my research, I created sequence diagrams that identified all the necessary states within the workflow. I designed UIs for each state, first as wireframes to refine with internal subject matter experts, then as low-fidelity clickable mockups that I presented to internal stakeholders. I set two experience principles to guide the design of Highlight and explain my design decisions to stakeholders.
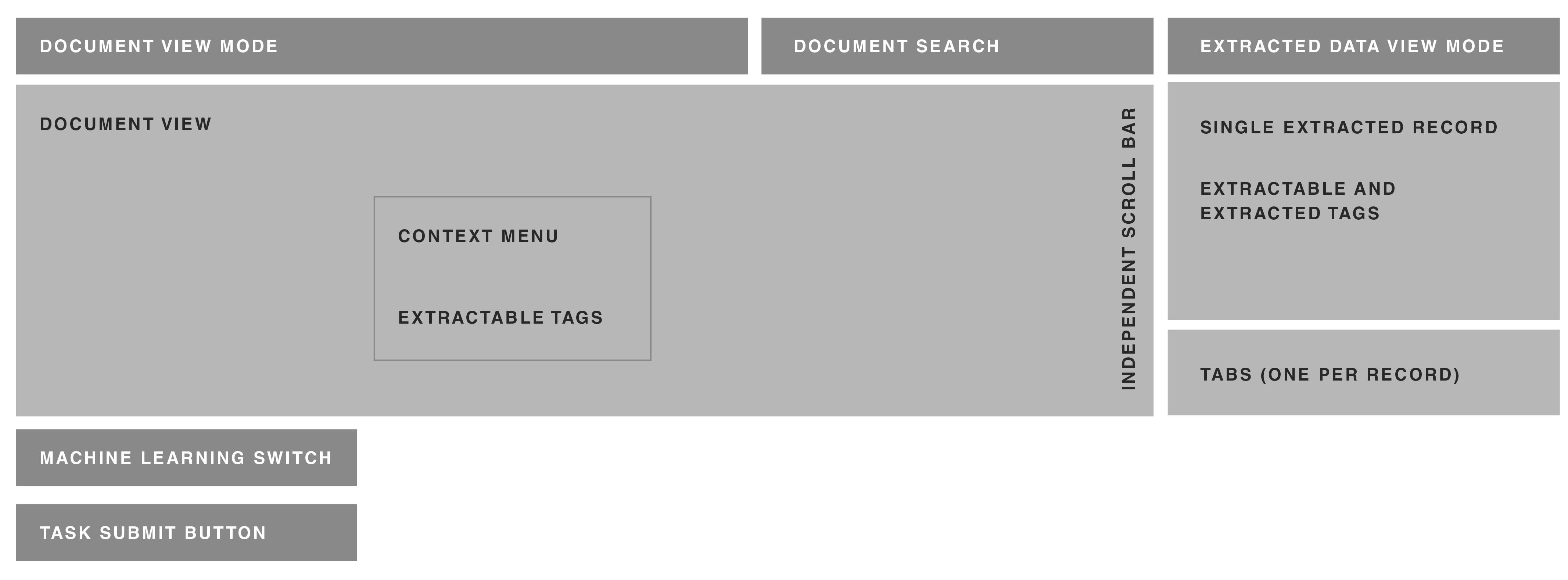
Visibility and flow of data was the first design principle. Since the goal of the project was to transform the data from a PDF into a standardized data store, it was only appropriate that the worker should have better visibility into both the initial and the desired state. The process would be resilient to failures of our backend to carry the data from one step to the next.
In order to eliminate the need for splitting tasks and improve the data flow, I designed a way for workers to define semantic relationships. The tool lets them quickly assign data from each row of the table into a separate group of tags. The panels scroll independently of one another, so workers would always see the tags that they are working on.
If the OCR malfunctioned, workers would be able to view the source PDF directly, and manually enter the information in a way that was similar to the tool they were used to. Finally, regardless of how they entered this data, their input would be normalized for categories such as country or currency, saving the client a lot of data cleaning work.
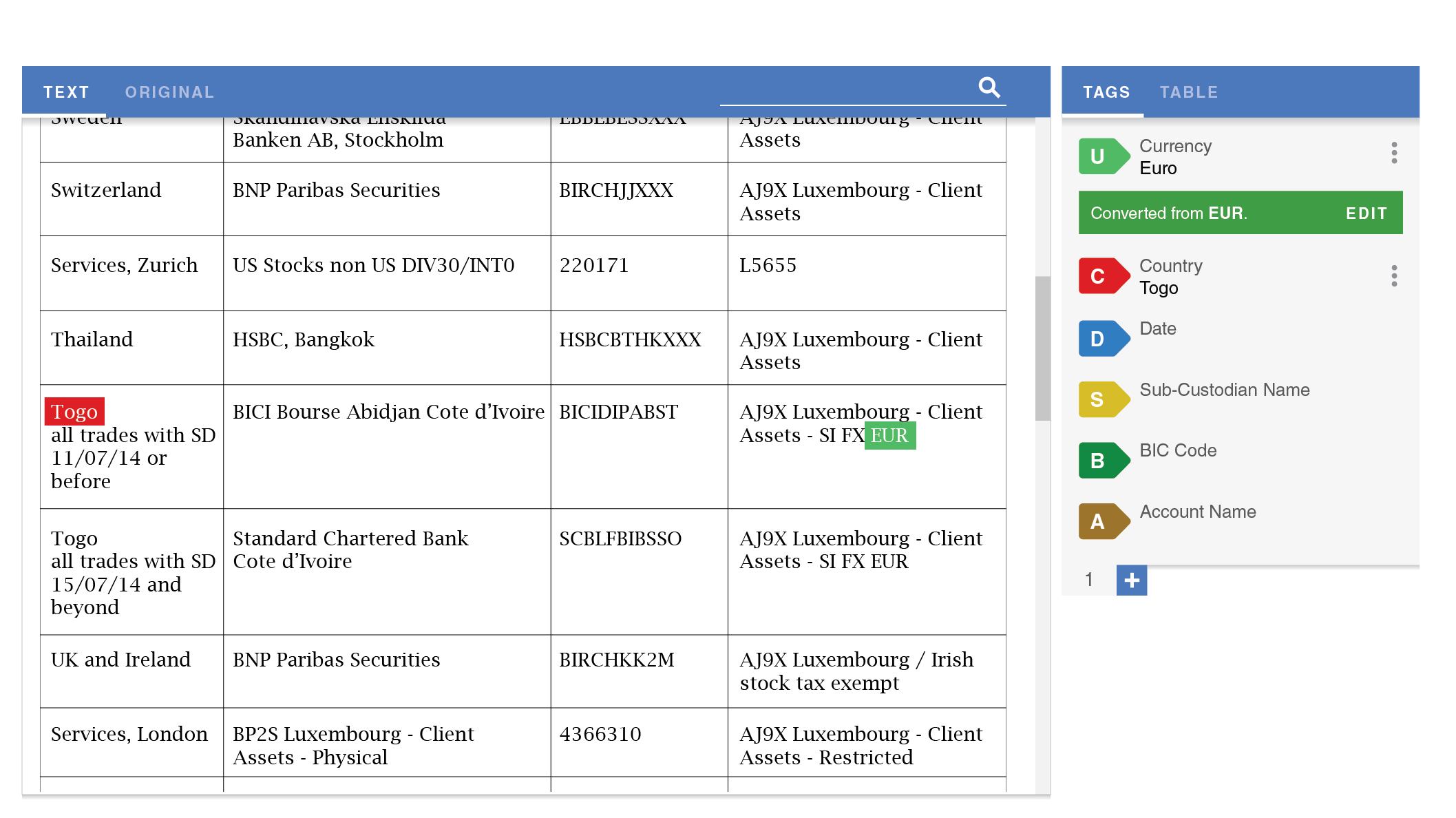
The second experience principle was efficiency. A lot of observed uses of the tool involved repeating actions, such as tagging each item in the Country column as the name of a country. Incorporating batch actions would drastically speed up document extraction and make it less tedious for workers to perform these tasks.
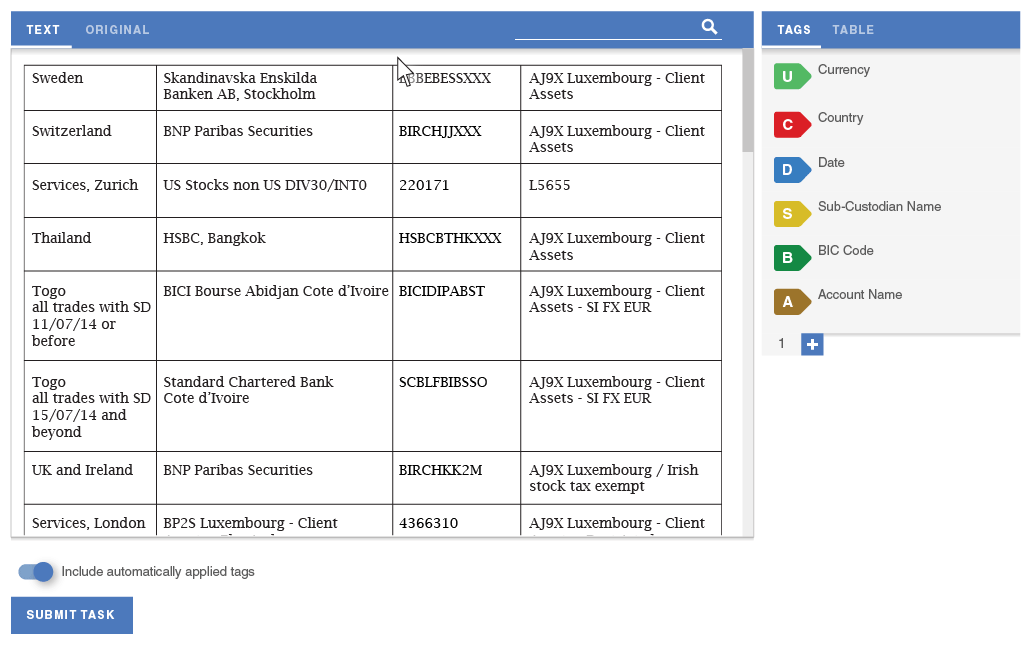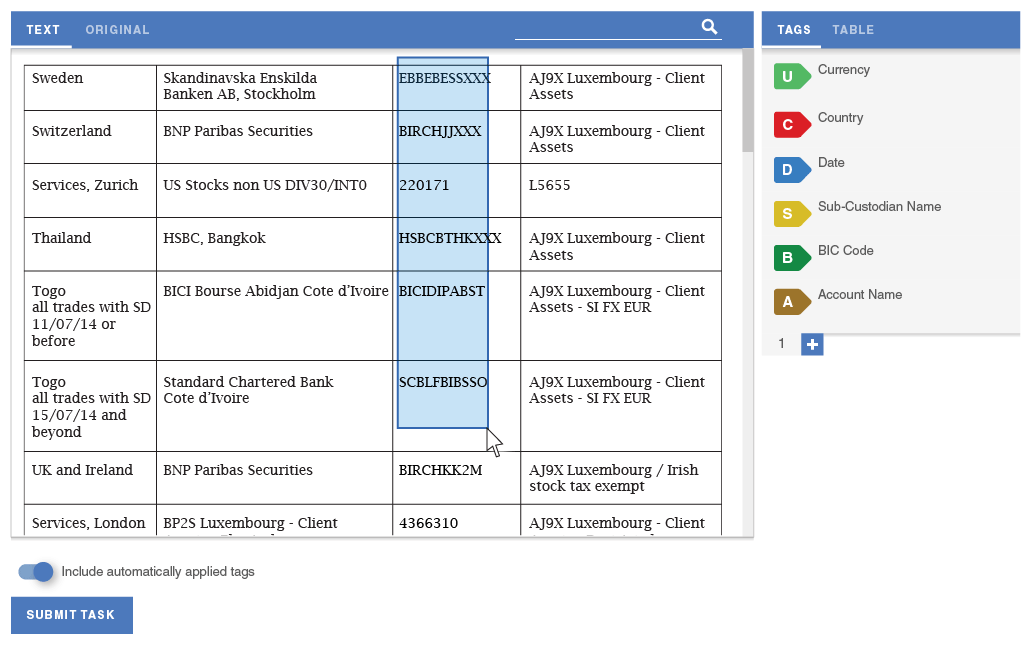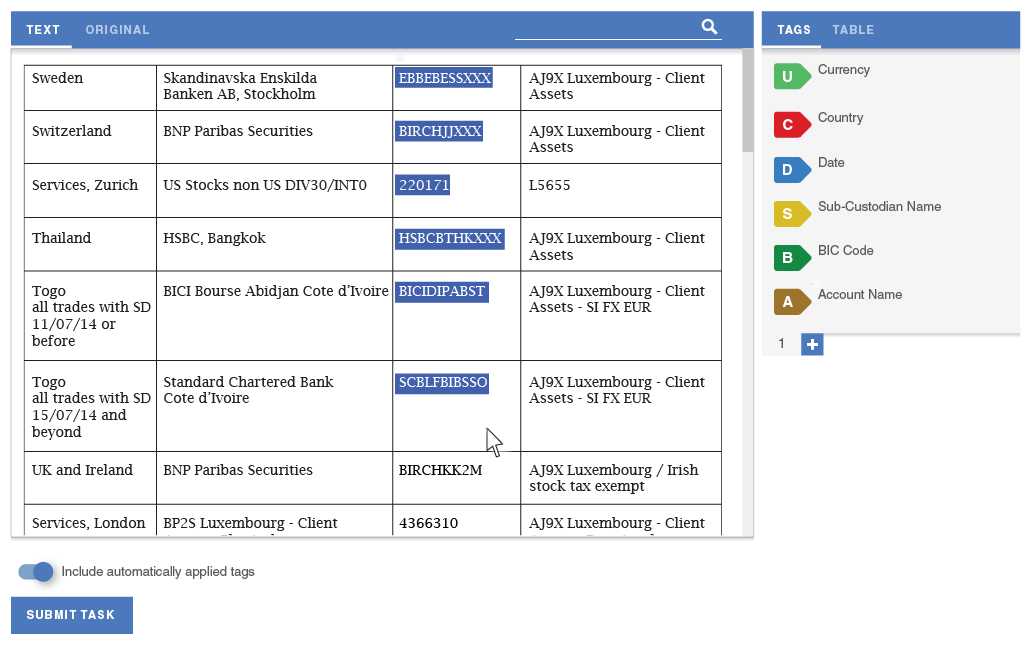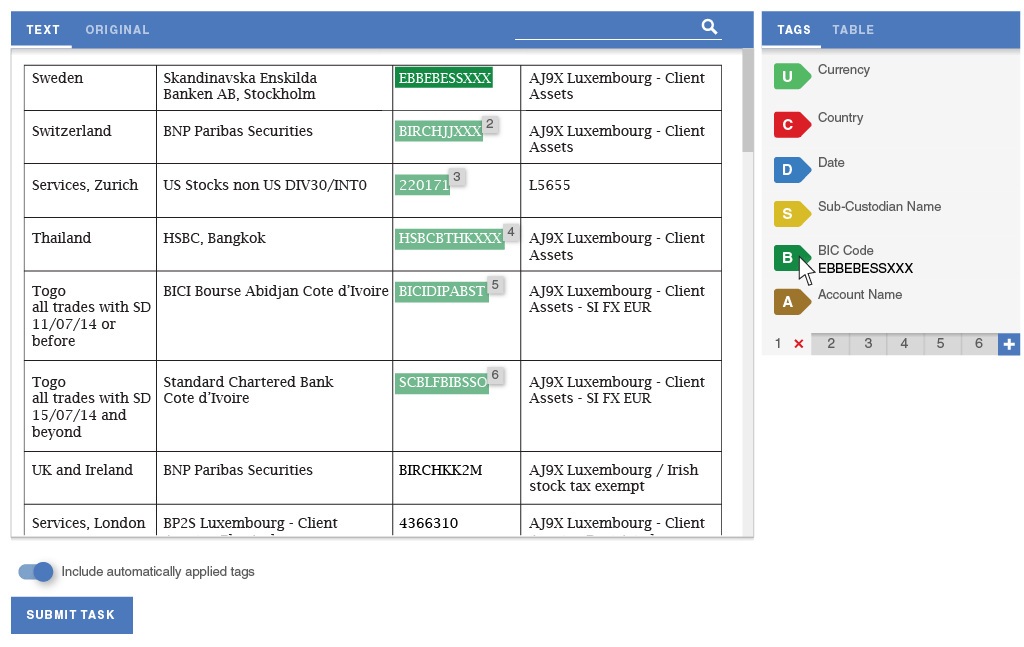
My collaboration with our data scientists led us to consider Highlight as an opportunity to test a new implementation of our machine learning algorithm that could run in the worker's browser, making suggestions. The worker could assume a direct supervisory role over the machine learning by deleting incorrect suggestions and accepting correct ones.
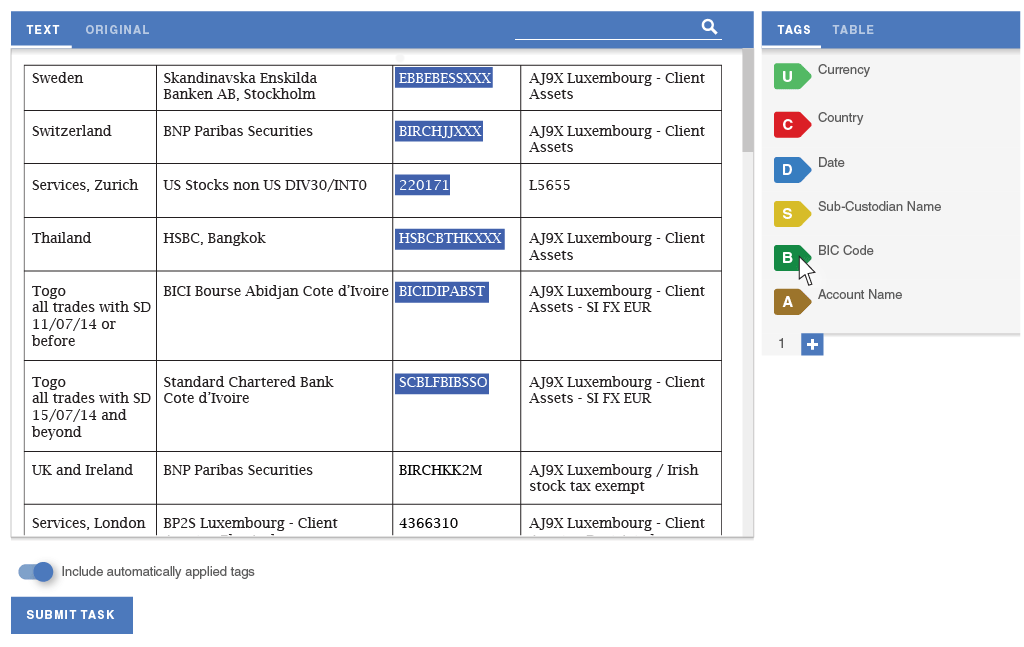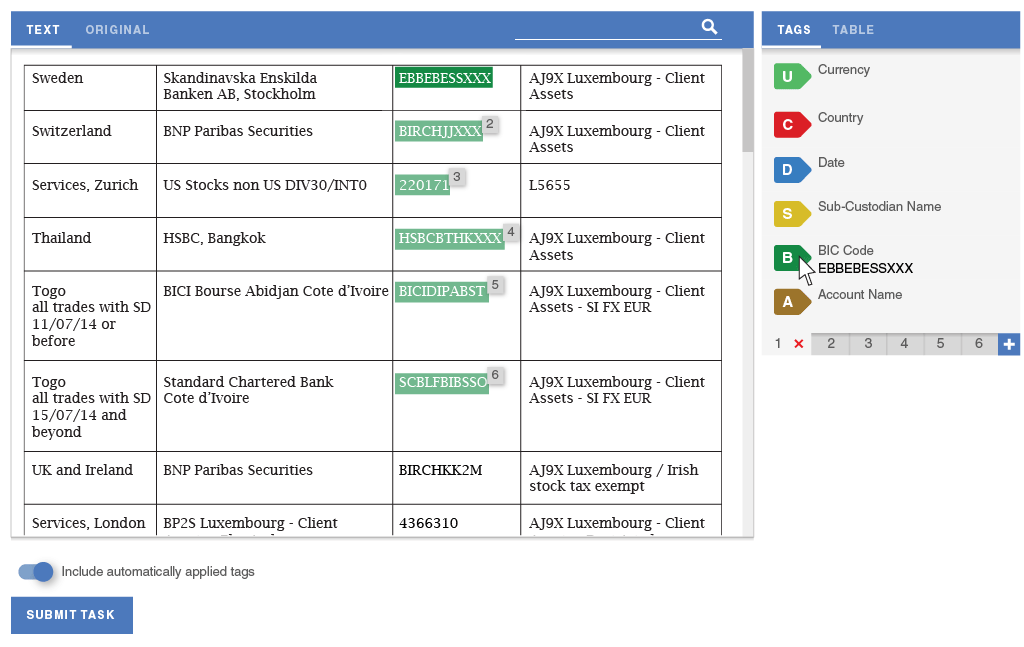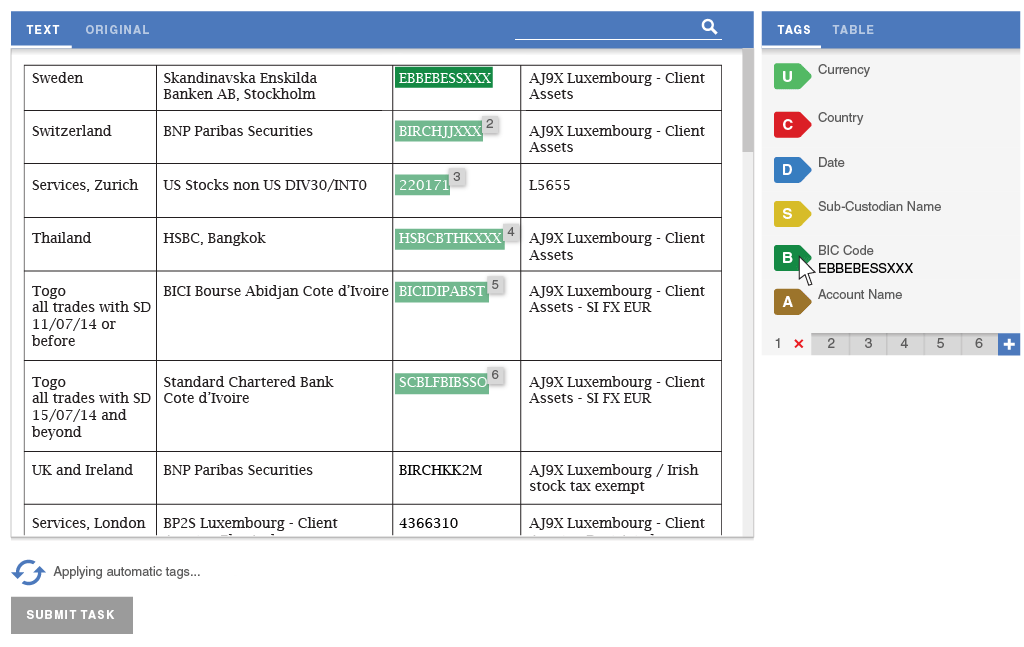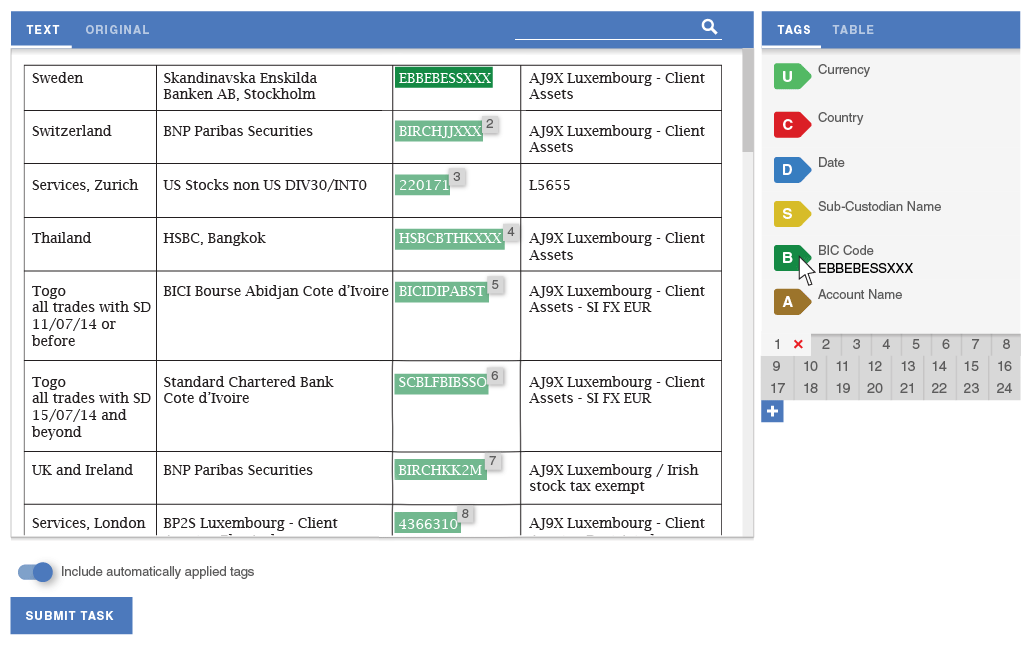
After early experiments were successful in drastically reducing task completion time, I demoed the idea to senior management. While it was outside of the original scope, I was able to get them excited enough for this feature to prioritize it over other projects, and assign an additional developer to implement the data science team's prototype.
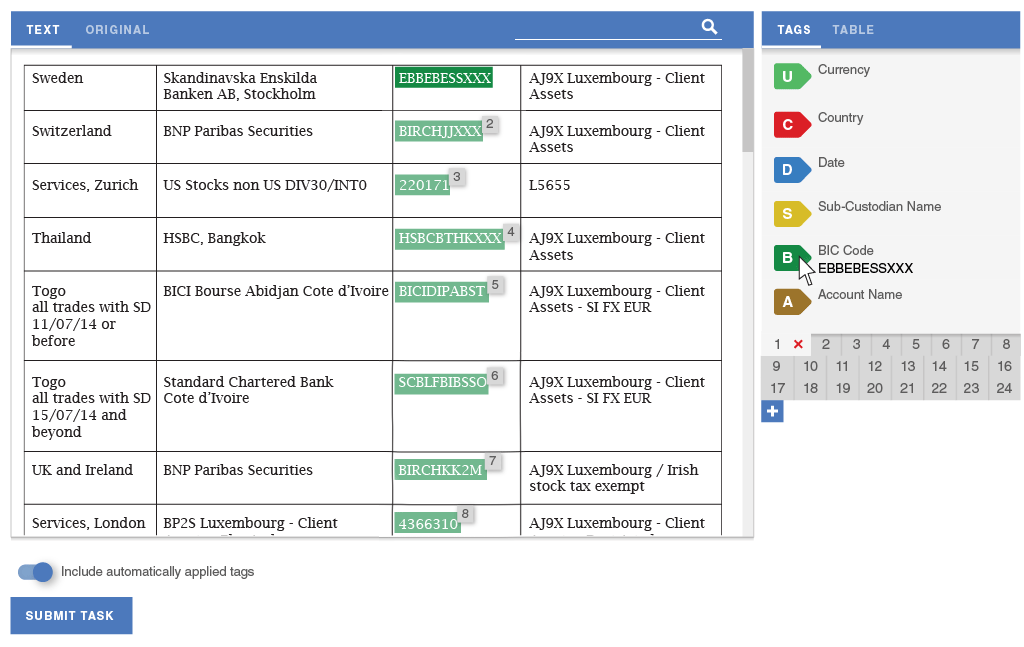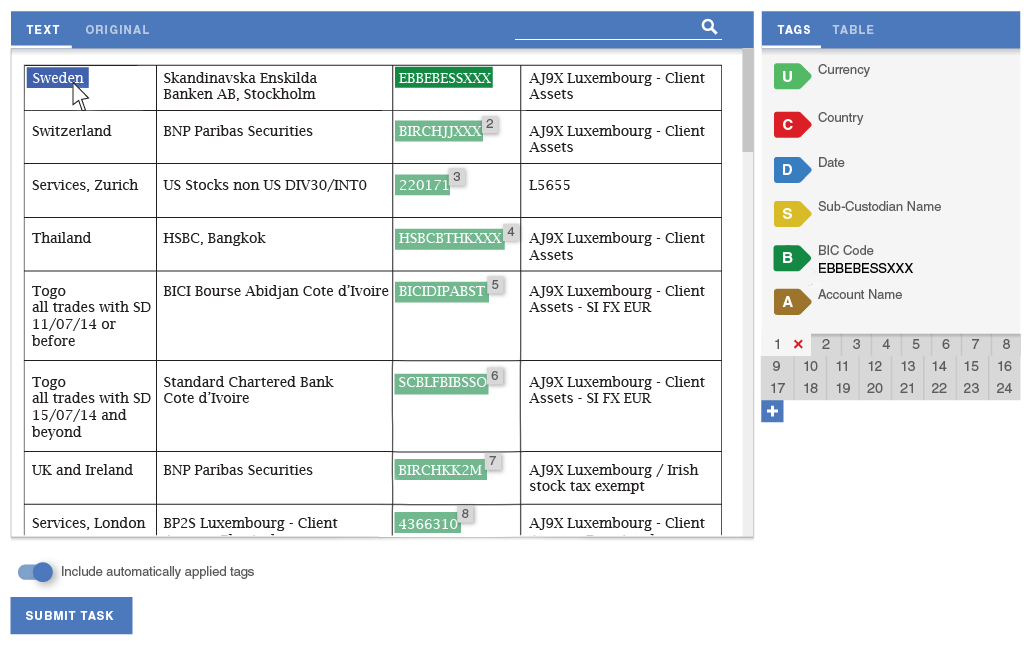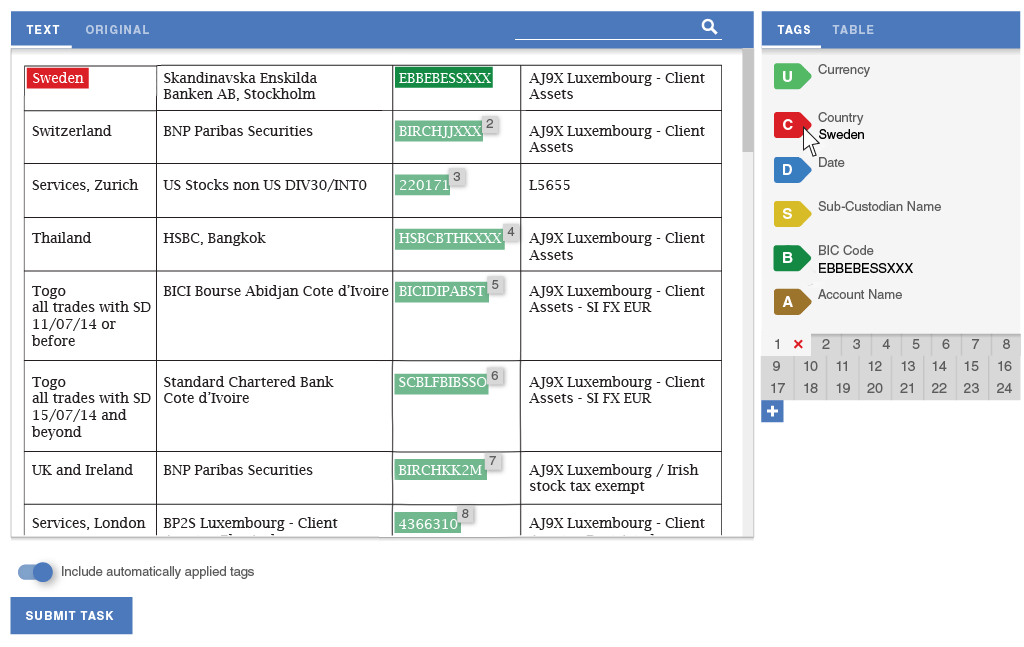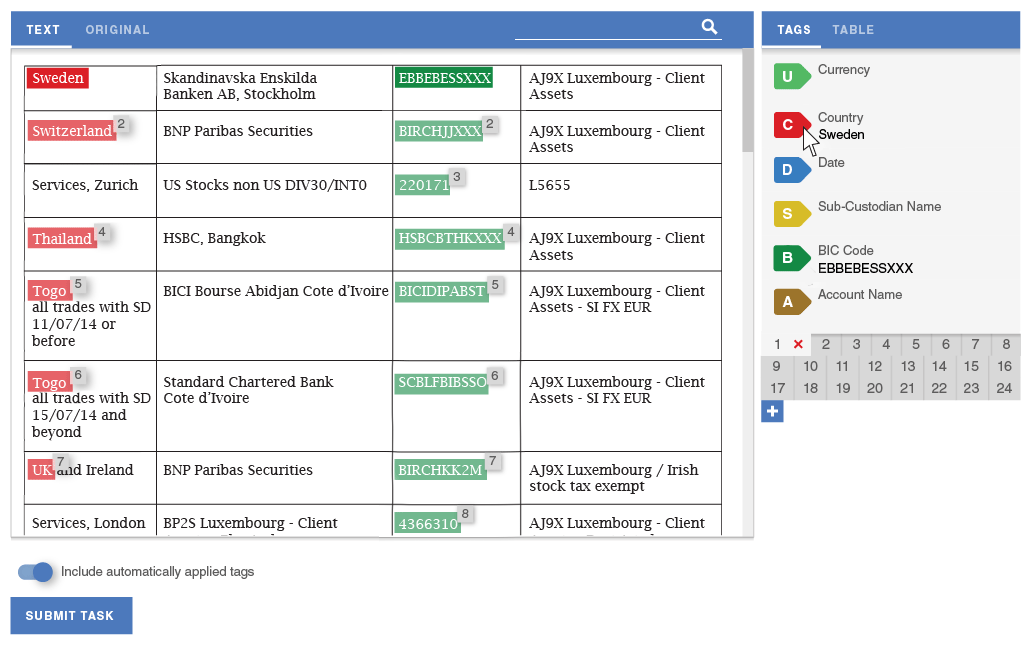
After scaling the scope down to a batch of work that could be implemented during the Proof of Concept period, I designed high-fidelity mockups for the reduced slice of the experience and recorded their requirements as JIRA stories.
Due to the limited number of developers available for implementing Highlight, I took on the role of a developer, writing front-end code alongside two engineers. I focused my efforts on interface animation and areas where multiple user flows collided, as well as User Acceptance Testing. I prioritized completing end-to-end user flows one at a time, which allowed me to frequently demo new features to internal stakeholders and quickly incorporate their feedback. This approach to feature development allowed us to deliver several iterations of Highlight throughout the Proof of Concept timeframe.
Outcomes
When all stakeholders were satisfied with testing results and stability, we reorganized the document processing workflow to use Highlight instead of the legacy tagging tool, and released it to the client's internal workforce. Workers were able to extract data much faster than before – a document that used to take 30 minutes with their original in-house method could be done in as little as 30 seconds when going through the Highlight workflow. Ultimately, this project led to an 80% reduction in full-time employees dealing with document extraction. Workers no longer felt the need to go off-tool due to the frustrating user experience, and were able to process all but the gnarliest PDFs within the Highlight tool.
The straightforward user experience also allowed Workfusion to trial Highlight for public crowd usage, where time spent learning a new tool can be costly for workers who are paid per completed task. With incremental adjustments, Highlight proved to be easy enough for these workers to use, and Workfusion fully retired the original tool.
Learning outcomes
Going into this project, I had no product management training. It was challenging at first to switch from higher-level value-focused descriptions and demonstrations of my designs to low-level, high-detail state by state requirements that developers needed in order to implement the functionality. Part of why I contributed to the coding of Highlight was because I had difficulty explaining some of the more complex interactions.
However, diving into that level of detail made it difficult for me to focus on the bigger picture, and my flows ended up not being fully thought out in several areas. Encountering these bugs during a demo to stakeholders was embarrassing, but I was able to use the opportunity to get another developer for my team, freeing me up to focus on the product manager's role.
I did find that editing the code myself was a very effective strategy for situations where the developers had nearly, but not completely, followed requirements. Closing that gap without needing to hold demos and meetings greatly accelerated the pace of our work.
I also started off on shaky ground when demoing our progress to senior stakeholders. The team received a mixture of feedback about bugs and requests for new features, and I found it hard to push back against my manager's demands. This led to several cycles where we could not quickly hold another demo, since our new code branch would introduce bugs from new features even as we fixed bugs in the old ones. Realizing that it would take time for us to meet their requirements, the stakeholders relented and gave us the room to adopt a release cadence where we could fix known bugs, and only then open a branch for new features.